Задача распределить файловые группы на разные диски. Чем больше операций чтения и записи в файловой группе тем быстрее будут выделены диски и RAID.
Есть база весит 1.5 тб. В ней файловые группы:
 Нужно подумать как их распределить.
Нужно подумать как их распределить.
База TempDb у нас находится на ssd в зеркале.Размер диска 370 гб. TempDb разбит на файлы по рекомендации майкрософт

Сначала был выполнен скрипт накопление статистики ожидания из статьи https://habrahabr.ru/post/216309/
WITH [Waits] AS
(SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT')
)
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
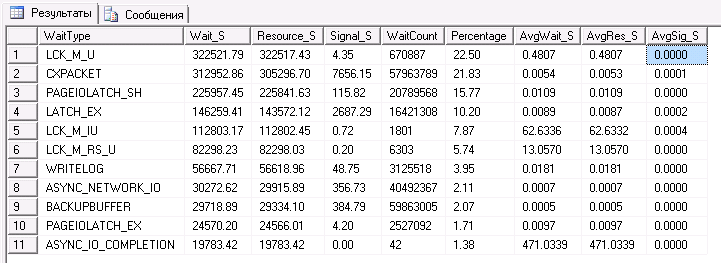
[spoiler show=”Расшифровка”]
- 505: CXPACKET
Означает параллелизм, но не обязательно в нем проблема. Поток-координатор в параллельном запросе всегда накапливает эти ожидания. Если параллельные потоки не заняты работой или один из потоков заблокирован, то ожидающие потоки также накапливают ожидание CXPACKET, что приводит к более быстрому накоплению статистики по этому типу — в этом и проблема. Один поток может иметь больше работы, чем остальные, и по этой причине весь запрос блокируется, пока долгий поток не закончит свою работу. Если этот тип ожидания совмещен с большими цифрами ожидания PAGEIOLATCH_XX, то это может быть сканирование больших таблиц по причине некорректных некластерных индексов или из-за плохого плана выполнения запроса. Если это не является причиной, вы можете попробовать применение опции MAXDOP со значениями 4, 2, или 1 для проблемных запросов или для всего экземпляра сервера (устанавливается на сервере параметром «max degree of parallelism»). Если ваша система основана на схеме NUMA, попробуйте установить MAXDOP в значение, равное количеству процессоров в одном узле NUMA для того, чтобы определить, не в этом ли проблема. Вам также нужно определить эффект от установки MAXDOP на системах со смешанной нагрузкой. Если честно, я бы поиграл с параметром «cost threshold for parallelism» (поднял его до 25 для начала), прежде чем снижать значение MAXDOP для всего экземпляра. И не забывайте про регулятор ресурсов (Resource Governor) в Enterprise версии SQL Server 2008, который позволяет установить количество процессоров для конкретной группы соединений с сервером. - 304: PAGEIOLATCH_XX
Вот тут SQL Server ждет чтения страницы данных с диска в память. Этот тип ожидания может указывать на проблему в системе ввода/вывода (что является первой реакцией на этот тип ожидания), но почему система ввода/вывода должна обслуживать такое количество чтений? Возможно, давление оказывает буферный пул/память (недостаточно памяти для типичной нагрузки), внезапное изменение в планах выполнения, приводящее к большим параллельным сканированиям вместо поиска, раздувание кэша планов или некоторые другие причины. Не стоит считать, что основная проблема в системе ввода/вывода. - 275: ASYNC_NETWORK_IO
Здесь SQL Server ждет, пока клиент закончит получать данные. Причина может быть в том, что клиент запросил слишком большое количество данных или просто получает их ооочень медленно из-за плохого кода — я почти никогда не не видел, чтобы проблема заключалась в сети. Клиенты часто читают по одной строке за раз — так называемый RBAR или «строка за агонизирующей строкой»(Row-By-Agonizing-Row) — вместо того, чтобы закешировать данные на клиенте и уведомить SQL Server об окончании чтения немедленно. - 112: WRITELOG
Подсистема управления логом ожидает записи лога на диск. Как правило, означает, что система ввода/ввода не может обеспечить своевременную запись всего объема лога, но на высоконагруженных системах это может быть вызвано общими ограничениями записи лога, что может означать, что вам следует разделить нагрузку между несколькими базами, или даже сделать ваши транзакции чуть более долгими, чтобы уменьшить количество записей лога на диск. Для того, чтобы убедиться, что причина в системе ввода/вывода, используйте DMV sys.dm_io_virtual_file_stats для того, чтобы изучить задержку ввода/вывода для файла лога и увидеть, совпадает ли она с временем задержки WRITELOG. Если WRITELOG длится дольше, вы получили внутреннюю конкуренцию за запись на диск и должны разделить нагрузку. Если нет, выясняйте, почему вы создаете такой большой лог транзакций. Здесь (англ.) и здесь (англ.) можно почерпнуть некоторые идеи.
(прим переводчика: следующий запрос позволяет в простом и удобном виде получить статистику задержек ввода/вывода для каждого файла каждой базы данных на сервере: - 109: BROKER_RECEIVE_WAITFOR
Здесь Service Broker ждет новые сообщения. Я бы рекомендовал добавить это ожидание в список исключаемых и заново выполнить запрос со статистикой ожидания. - 086: MSQL_XP
Здесь SQL Server ждет выполнения расширенных хранимых процедур. Это может означать наличие проблем в коде ваших расширенных хранимых процедур. - 074: OLEDB
Как и предполагается из названия, это ожидание взаимодействия с использованием OLEDB — например, со связанным сервером. Однако, OLEDB также используется в DMV и командой DBCC CHECKDB, так что не думайте, что проблема обязательно в связанных серверах — это может быть внешняя система мониторинга, чрезмерно использующая вызовы DMV. Если это и в самом деле связанный сервер — тогда проведите анализ ожиданий на связанном сервере и определите, в чем проблема с производительностью на нем. - 054: BACKUPIO
Показывает, когда вы делаете бэкап напрямую на ленту, что ооочень медленно. Я бы предпочел отфильтровать это ожидание. (прим. переводчика: я встречался с этим типом ожиданий при записи бэкапа на диск, при этом бэкап небольшой базы выполнялся очень долго, не успевая выполниться в технологический перерыв и вызывая проблемы с производительностью у пользователей. Если это ваш случай, возможно дело в системе ввода/вывода, используемой для бэкапирования, необходимо рассмотреть возможность увеличения ее производительности либо пересмотреть план обслуживания (не выполнять полные бэкапы в короткие технологические перерывы, заменив их дифференциальными)) - 041: LCK_M_XX
Здесь поток просто ждет доступа для наложения блокировки на объект и означает проблемы с блокировками. Это может быть вызвано нежелательной эскалацией блокировок или плохим кодом, но также может быть вызвано тем, что операции ввода/вывода занимают слишком долгое время и держат блокировки дольше, чем обычно. Посмотрите на ресурсы, связанные с блокировками, используя DMV sys.dm_os_waiting_tasks. Не стоит считать, что основная проблема в блокировках. - 032: ONDEMAND_TASK_QUEUE
Это нормально и является частью системы фоновых задач (таких как отложенный сброс, очистка в фоне). Я бы добавил это ожидание в список исключаемых и заново выполнил запрос со статистикой ожидания. - 031: BACKUPBUFFER
Показывает, когда вы делаете бэкап напрямую на ленту, что ооочень медленно. Я бы предпочел отфильтровать это ожидание. - 027: IO_COMPLETION
SQL Server ждет завершения ввода/вывода и этот тип ожидания может быть индикатором проблемы с системой ввода/вывода. - 024: SOS_SCHEDULER_YIELD
Чаще всего это код, который не попадает в другие типы ожидания, но иногда это может быть конкуренция в циклической блокировке. - 022: DBMIRROR_EVENTS_QUEUE
022: DBMIRRORING_CMD
Эти два типа показывают, что система управления зеркальным отображением (database mirroring) сидит и ждет, чем бы ей заняться. Я бы добавил эти ожидания в список исключаемых и заново выполнил запрос со статистикой ожидания. - 018: PAGELATCH_XX
Это конкуренция за доступ к копиям страниц в памяти. Наиболее известные случаи — это конкуренция PFS, SGAM, и GAM, возникающие в базе tempdb при определенных типах нагрузок (англ.). Для того, чтобы выяснить, за какие страницы идет конкуренция, вам нужно использовать DMV sys.dm_os_waiting_tasks для того, чтобы выяснить, из-за каких страниц возникают блокировки. По проблемам с базой tempdb Роберт Дэвис (его блог, твиттер) написал хорошую статью, показывающую, как их решать (англ.) Другая частая причина, которую я видел — часто обновляемый индекс с конкурирующими вставками в индекс, использующий последовательный ключ (IDENTITY). - 016: LATCH_XX
Это конкуренция за какие либо не страничные структуры в SQL Server’е — так что это не связано с вводом/выводом и данными вообще. Причину такого типа задержки может быть достаточно сложно понять и вам необходимо использовать DMV sys.dm_os_latch_stats. - 013: PREEMPTIVE_OS_PIPEOPS
Здесь SQL Server переключается в режим упреждающего планирования для того, чтобы запросить о чем-то Windows. Этот тип ожидания был добавлен в 2008 версии и еще не был документирован. Самый простой способ выяснить, что он означает — это убрать начальные PREEMPTIVE_OS_ и поискать то, что осталось, в MSDN — это будет название API Windows. - 013: THREADPOOL
Такой тип говорит, что недостаточно рабочих потоков в системе для того, чтобы удовлетворить запрос. Обычно причина в большом количестве сильно параллелизованных запросов, пытающихся выполниться. (прим. переводчика: также это может быть намеренно урезанное значение параметра сервера «max worker threads») - 009: BROKER_TRANSMITTER
Здесь Service Broker ждет новых сообщений для отправки. Я бы рекомендовал добавить это ожидание в список исключаемых и заново выполнить запрос со статистикой ожидания. - 006: SQLTRACE_WAIT_ENTRIES
Часть слушателя (trace) SQL Server’а. Я бы рекомендовал добавить это ожидание в список исключаемых и заново выполнить запрос со статистикой ожидания. - 005: DBMIRROR_DBM_MUTEX
Это один из недокументированных типов и в нем конкуренция возникает за отправку буфера, который делится между сессиями зеркального отображения (database mirroring). Может означать, что у вас слишком много сессий зеркального отображения. - 005: RESOURCE_SEMAPHORE
Здесь запрос ждет память для исполнения (память, используемая для обработки операторов запроса — таких, как сортировка). Это может быть недостаток памяти при конкурентной нагрузке. - 003: PREEMPTIVE_OS_AUTHENTICATIONOPS
003: PREEMPTIVE_OS_GENERICOPS
Здесь SQL Server переключается в режим упреждающего планирования для того, чтобы запросить о чем-то Windows. Этот тип ожидания был добавлен в 2008 версии и еще не был документирован. Самый простой способ выяснить, что он означает — это убрать начальные PREEMPTIVE_OS_ и поискать то, что осталось, в MSDN — это будет название API Windows. - 003: SLEEP_BPOOL_FLUSH
Это ожидание можно часто увидеть и оно означает, что контрольная точка ограничивает себя для того, чтобы избежать перегрузки системы ввода/вывода. Я бы рекомендовал добавить это ожидание в список исключаемых и заново выполнить запрос со статистикой ожидания. - 002: MSQL_DQ
Здесь SQL Server ожидает, пока выполнится распределенный запрос. Это может означать проблемы с распределенными запросами или может быть просто нормой. - 002: RESOURCE_SEMAPHORE_QUERY_COMPILE
Когда в системе происходит слишком много конкурирующих перекомпиляций запросов, SQL Server ограничивает их выполнение. Я не помню уровня ограничения, но это ожидание может означать излишнюю перекомпиляцию или, возможно, слишком частое использование одноразовых планов. - 001: DAC_INIT
Я никогда раньше этого не видел и BOL говорит, что причина в инициализации административного подключения. Я не могу представить, как это может быть преимущественным ожиданием на чьей либо системе… - 001: MSSEARCH
Этот тип является нормальным при полнотекстовых операциях. Если это преимущественное ожидание, это может означать, что ваша система тратит больше всего времени на выполнение полнотекстовых запросов. Вы можете рассмотреть возможность добавить этот тип ожидания в список исключаемых. - 001: PREEMPTIVE_OS_FILEOPS
001: PREEMPTIVE_OS_LIBRARYOPS
001: PREEMPTIVE_OS_LOOKUPACCOUNTSID
001: PREEMPTIVE_OS_QUERYREGISTRY
Здесь SQL Server переключается в режим упреждающего планирования для того, чтобы запросить о чем-то Windows. Этот тип ожидания был добавлен в 2008 версии и еще не был документирован. Самый простой способ выяснить, что он означает — это убрать начальные PREEMPTIVE_OS_ и поискать то, что осталось, в MSDN — это будет название API Windows. - 001: SQLTRACE_LOCK
Часть слушателя (trace) SQL Server’а. Я бы рекомендовал добавить это ожидание в список исключаемых и заново выполнить запрос со статистикой ожидания.
[/spoiler]
Можно сбросить статистику что бы собрать её заного
DBCC SQLPERF (N'sys.dm_os_wait_stats', CLEAR); GO
Определились что у нас узкое место блокировки и файловая система. Так как мучить программеров нет смысла что бы они изменили код. Начали мучить файловую систему. Тоесть переносить на HP MSA 2040:

Дальше решили узнать какая файловая группа самая прожорлевая в плане чтения и записи. Был выполнен скрипт из статьи https://technet.microsoft.com/ru-ru/library/jj643251.aspx
SELECT
DB_NAME(a.database_id) AS [Database Name]
--,a.FILE_ID
,i.name
,a.io_stall_read_ms
,a.num_of_reads
,CAST(a.io_stall_read_ms / (1.0 + a.num_of_reads) AS NUMERIC(10 ,1)) AS [avg_read_stall_ms]
,a.io_stall_write_ms
,a.num_of_writes
,CAST(
a.io_stall_write_ms / (1.0 + a.num_of_writes) AS NUMERIC(10 ,1)
) AS [a.avg_write_stall_ms]
,a.io_stall_read_ms + a.io_stall_write_ms AS [io_stalls]
,a.num_of_reads + a.num_of_writes AS [total_io]
,CAST(
(a.io_stall_read_ms + a.io_stall_write_ms) / (1.0 + a.num_of_reads + a.num_of_writes) AS NUMERIC(10 ,1)
) AS [avg_io_stall_ms]
FROM
sys.dm_io_virtual_file_stats(NULL ,NULL)a
INNER JOIN
sys.master_files i
ON a.file_id = i.file_id
AND a.database_id = i.database_id
WHERE i.database_id in ('7')
ORDER BY
avg_io_stall_ms DESC;
Результат:
 Результат в таблице:
Результат в таблице:
 Конечный результат. Распределение файловых групп по дискам:
Конечный результат. Распределение файловых групп по дискам:

ссылка на таблицу https://docs.google.com/spreadsheets/d/1CxU8qVb6zGG9176aIB8PSj7r34EQs7mXttDYawGi7lw/edit?usp=sharing